את העבודה הובילה אריאל ברוך, מסטרנטית תותחית מהמעבדה שלנו שהקרדיט לכל זה מגיע לה, אני תרמתי למחקר בעיקר את מימוש הרעיון הראשוני של שילוב הדוגמאות, וזה המקום גם להודות לשלושת המנחים של העבודה: פרופ' לירן כרמל מהמחלקה לגנטיקה, פרופ' ערן משורר מהמרכז למדעי המוח ומגנטיקה, ופרופ' בנימין יקיר, ראש המחלקה לסטטיסטיקה באוניברסיטה העברית
המאמר, שהתפרסם בכתב העת המדעי הנהדר Nucleic Acid Research, כבר זמין אונליין, ותוכלו לקרוא אותו כאן.
אני רוצה להודות לתומכי הפטריאון של הבלוג, ובראשם למתן רינג, עינבל רמות, שרה עטיה ושריתי סקויאר, התומכים המובילים. אם התוכן עניין אתכם, אני מזמין אתכם להפוך גם לתומכים, לעזור ל”סיור מוחות” לצמוח ולקבל מגוון רחב של הטבות כמו תכנים בלעדיים, יכולת להשפיע על הנושאים וצפייה בפוסטים לפני כולם. פרטים נוספים כאן
הצטרפו לרשימת התפוצה של הבלוג וקבלו את התכנים ישירות למייל
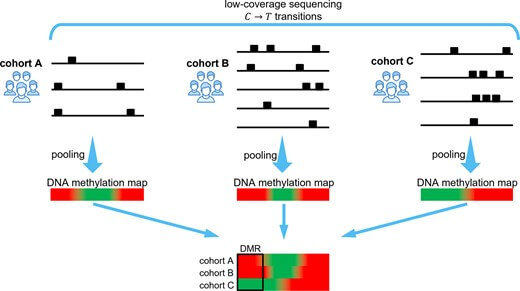
כיצד הופכים שביבי מידע מדגימות דנ"א שונות באוכלוסיה אחת לכדי הבנה של האפיגנטיקה שהתרחשה באותה האוכלוסיה?
קרדיט: Barouch et al. NAR (2024)